5. 퀴즈 통계
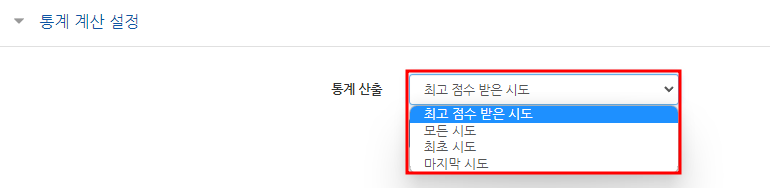
1. 통계 계산 설정
- 최고 점수 받은 시도(Highest graded attempt): 퀴즈 응시가 여러 번 가능할 때 가장 높은 점수를 받은 통계를 표시합니다.
- 모든 시도(All attempts): 퀴즈 응시가 여러 번 가능할 때, 응시했던 모든 시도의 통계를 표시합니다.
- 최초 시도(First attempts): 퀴즈 응시가 여러 번 가능할 때, 첫번째 응시의 통계를 표시합니다.
- 마지막 시도(Last attempts): 퀴즈 응시가 여러 번 가능할 때, 마지막 응시의 통계를 표시합니다.
2. 퀴즈 소개
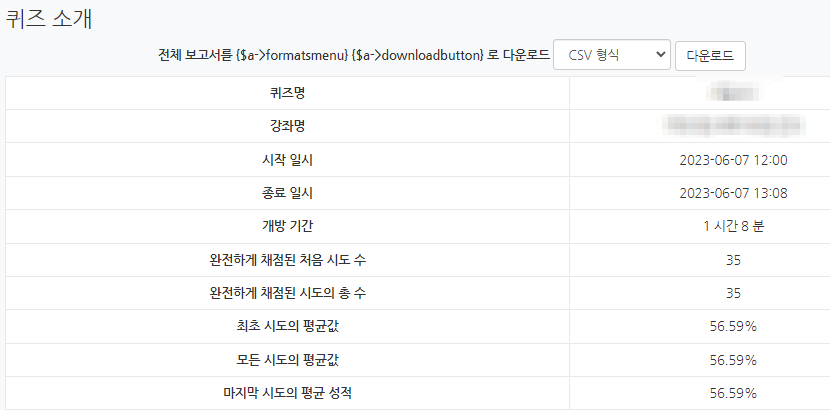
- 퀴즈명(Quiz name): 해당 퀴즈의 이름입니다.
- 강좌명(Course name): 퀴즈가 속해 있는 강좌의 이름입니다.
- 시작 일시(Open the quiz): 퀴즈 응시가 시작한 날짜와 시간입니다.
- 종료 일시Close the quiz): 퀴즈가 마감된 날짜와 시간입니다.
- 개방 기간(Open for): 퀴즈 응시가 가능하도록 설정되었던 기간을 의미합니다.
- 완전하게 채점된 처음 시도 수(Number of complete graded first attempts): 학습자가 퀴즈를 처음 응시한 횟수를 나타냅니다.
- 완전하게 채점된 시도의 총 수(Total number of complete graded attempts): 학습자가 다수의 퀴즈 응시가 가능할 때, 퀴즈 응시의 총 합계를 나타냅니다.
- 최초 시도의 평균값(Average grade of first attempts): 학습자가 처음 응시한 퀴즈의 평균값을 나타냅니다.
- 모든 시도의 평균값(Average grade of all attempts): 학습자가 다수의 퀴즈 응시 가능할 때, 모든 응시의 평균 값을 나타냅니다.
-마지막 시도의 평균 성적(Average grade of last attempts 학습자가 다수의 퀴즈 응시 가능할 때, 마지막 응시의 평균 성적을 나타냅니다.
- 가장 높은 점수의 평균 성적(Average grade of highest graded attempts): 퀴즈 응시가 여러 번 가능할 때, 가장 높은 점수의 평균값을 나타냅니다.
- (최고 점수 받은 시도) 중앙값(Median grade (for highest graded attempt)): 퀴즈 응시가 여러 번 가능할 때, 최고 높은 성적을 받은 응시 성적의 중앙값을 나타냅니다.
- (최고 점수 받은 시도) 표준편차(Standard deviation): 퀴즈 응시가 여러 번 가능할 때, 최고 높은 성적을 받은 응시 성적의 표준편차를 나타냅니다.
- (최고 점수 받은 시도) 득점분포 비대칭도(Score distribution skewness): 퀴즈 응시가 여러 번 가능할 때, 최고 점수를 받은 응시 성적의 편포도를 나타냅니다.
- (최고 점수 받은 시도) 득점분포 첨도(Score distribution kurtosis): 점수 변별도의 대칭정도를 나타냅니다. -1,0에 가까울수록 좋으며, 너무 높거나(1.0이상) 낮은 경우 문항의 변별도가 떨어짐을 의미합니다.
- (최고 점수 받은 시도) 내적 일관성 계수(Coefficient of internal consistency): 퀴즈에 있는 문항의 일관성을 확인할 수 있는 수치입니다. 75%이상이면 충분하고, 64%미만이면 퀴즈를 수정하는 것을 추천합니다. 즉, 내적 일관성 계수가 높을수록 타당도가 높다고 볼 수 있습니다.
- (최고 점수 받은 시도) 오류율(Error ratio): 오류 비율을 나타내는 수치로 학습자들의 능력을 관계없이 문제가 출제되었을 가능성을 뜻합니다. 즉, 퀴즈의 내적 일관성 계수가 높을수록 오류율은 낮게 측정됩니다. 오류율이 낮을수록 문제의 신뢰도가 높다고 할 수 있습니다.
- (최고 점수 받은 시도) 표준오차(Standard error): 오차 비율에서 비롯되며, 퀴즈의 문항의 학습자들의 점수의 불확실성을 측정합니다. 즉, 표준오차가 높을수록 학습자들의 실질적인 점수는 낮음을 의미합니다.

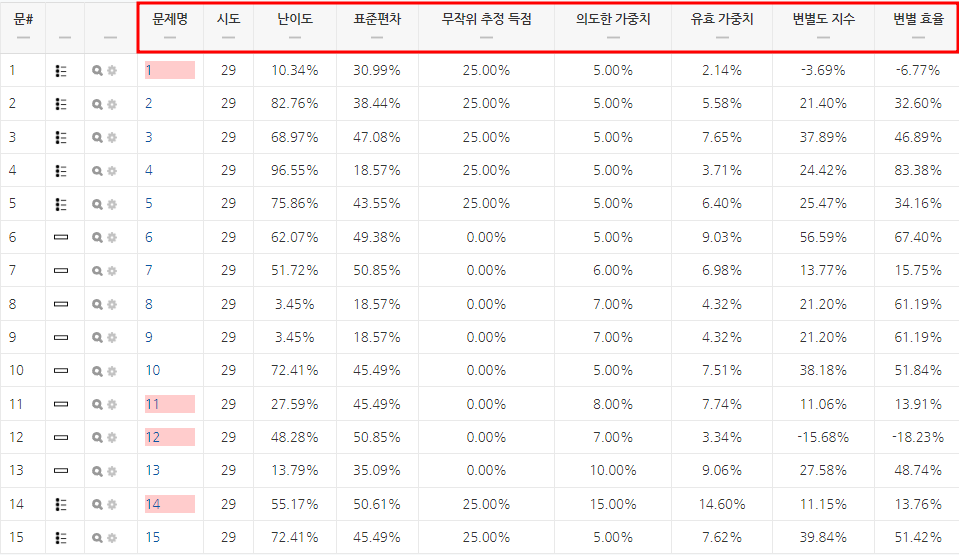
- 시도(Attempts): 퀴즈에 응시한 학습자의 수를 나타냅니다.
- 난이도(Facility index): 문항의 난이도를 나타냅니다.
- 표준편차(Standard deviation): 문제에 대한 점수의 변동량을 의미합니다.
- 무작위 추정 득점(Random guess score): 학습자가 문제를 찍어서 맞출 확률을 의미합니다.
- 의도한 가중치(Intended weight): 문제의 배점이 퀴즈 총 점수에서 차지하는 비중입니다.
- 유효 가중치(Effective weight): 퀴즈에서 문제가 차지하는 실질적인 비중입니다. 따라서 의도한 가중치와 가까울수록 좋습니다.
- 변별도 지수(Discrimination index): 문항의 점수와 퀴즈 전체 점수의 상관 관계로, 변별도 지수가 높을수록 좋은 문제임을 뜻합니다. 즉, 학습자들의 수준 차이를 확인할 수 있는 문제로 해당 문항을 맞춘 학습자가 퀴즈 전체 점수가 높을 가능성을 나타냅니다.
(50%이상: 매우 좋은 변별도 / 30~50%: 적절한 변별도/ 20~29%: 약한 변별도 / 0~19%: 매우 약한 변별도 / ve(점수가 없는 경우): 문항이 유효하지 않아 값이 산출되지 않은 경우)
- 변별 효율(Discriminative efficiency): 변별도 지수와 마찬가지로 해당 문항을 맞춘 학습자가 퀴즈 전체 점수가 높을 가능성을 나타냅니다.
- 빨간색으로 표시되는 문항: 변별 효율(Discriminative efficiency)의 값이 15%미만인 문항입니다. 즉, 학습자들의 수준을 변별할 가능성이 낮은 문제에 빨간 음영이 표시됩니다.